Что такое сэмплинг: цели и виды
Содержание:
Моделирование
Мы можем полностью отойти от теоретического решения и решить задачу «в лоб». Благодаря языку R теперь это сделать очень просто. Чтобы ответить на вопрос, в какую мы ошибку получим при сэмплировании, можно просто сделать тысячу сэмплирований и посмотреть, какую ошибку мы получаем.
Подход такой:
- Берем разные коэффициенты конверсии (от 0.01% до 50%).
- Берем 1000 сэмплов по 10, 100, 1000, 10000, 50000, 100000, 250000, 500000 элементов в выборке
- Считаем коэффициент конверсии по каждой группе сэмплов (1000 коэффициентов)
- Строим гистограмму по каждой группе сэмплов и определяем, в каких пределах лежат 60%, 80% и 90% наблюдаемых коэффициентов конверсии.
Код на R генерирующий данные:
В результате мы получаем следующую таблицу (дальше будут графики, но детали лучше видны в таблице).
| Коэффициент конверсии | Размер сэмпла | 5% | 10% | 20% | 80% | 90% | 95% |
|---|---|---|---|---|---|---|---|
| 0.0001 | 10 | ||||||
| 0.0001 | 100 | ||||||
| 0.0001 | 1000 | 0.001 | |||||
| 0.0001 | 10000 | 0.0002 | 0.0002 | 0.0003 | |||
| 0.0001 | 50000 | 0.00004 | 0.00004 | 0.00006 | 0.00014 | 0.00016 | 0.00018 |
| 0.0001 | 100000 | 0.00005 | 0.00006 | 0.00007 | 0.00013 | 0.00014 | 0.00016 |
| 0.0001 | 250000 | 0.000072 | 0.0000796 | 0.000088 | 0.00012 | 0.000128 | 0.000136 |
| 0.0001 | 500000 | 0.00008 | 0.000084 | 0.000092 | 0.000114 | 0.000122 | 0.000128 |
| 0.001 | 10 | ||||||
| 0.001 | 100 | 0.01 | |||||
| 0.001 | 1000 | 0.002 | 0.002 | 0.003 | |||
| 0.001 | 10000 | 0.0005 | 0.0006 | 0.0007 | 0.0013 | 0.0014 | 0.0016 |
| 0.001 | 50000 | 0.0008 | 0.000858 | 0.00092 | 0.00116 | 0.00122 | 0.00126 |
| 0.001 | 100000 | 0.00087 | 0.00091 | 0.00095 | 0.00112 | 0.00116 | 0.0012105 |
| 0.001 | 250000 | 0.00092 | 0.000948 | 0.000972 | 0.001084 | 0.001116 | 0.0011362 |
| 0.001 | 500000 | 0.000952 | 0.0009698 | 0.000988 | 0.001066 | 0.001086 | 0.0011041 |
| 0.01 | 10 | 0.1 | |||||
| 0.01 | 100 | 0.02 | 0.02 | 0.03 | |||
| 0.01 | 1000 | 0.006 | 0.006 | 0.008 | 0.013 | 0.014 | 0.015 |
| 0.01 | 10000 | 0.0086 | 0.0089 | 0.0092 | 0.0109 | 0.0114 | 0.0118 |
| 0.01 | 50000 | 0.0093 | 0.0095 | 0.0097 | 0.0104 | 0.0106 | 0.0108 |
| 0.01 | 100000 | 0.0095 | 0.0096 | 0.0098 | 0.0103 | 0.0104 | 0.0106 |
| 0.01 | 250000 | 0.0097 | 0.0098 | 0.0099 | 0.0102 | 0.0103 | 0.0104 |
| 0.01 | 500000 | 0.0098 | 0.0099 | 0.0099 | 0.0102 | 0.0102 | 0.0103 |
| 0.1 | 10 | 0.2 | 0.2 | 0.3 | |||
| 0.1 | 100 | 0.05 | 0.06 | 0.07 | 0.13 | 0.14 | 0.15 |
| 0.1 | 1000 | 0.086 | 0.0889 | 0.093 | 0.108 | 0.1121 | 0.117 |
| 0.1 | 10000 | 0.0954 | 0.0963 | 0.0979 | 0.1028 | 0.1041 | 0.1055 |
| 0.1 | 50000 | 0.098 | 0.0986 | 0.0992 | 0.1014 | 0.1019 | 0.1024 |
| 0.1 | 100000 | 0.0987 | 0.099 | 0.0994 | 0.1011 | 0.1014 | 0.1018 |
| 0.1 | 250000 | 0.0993 | 0.0995 | 0.0998 | 0.1008 | 0.1011 | 0.1013 |
| 0.1 | 500000 | 0.0996 | 0.0998 | 0.1 | 0.1007 | 0.1009 | 0.101 |
| 0.5 | 10 | 0.2 | 0.3 | 0.4 | 0.6 | 0.7 | 0.8 |
| 0.5 | 100 | 0.42 | 0.44 | 0.46 | 0.54 | 0.56 | 0.58 |
| 0.5 | 1000 | 0.473 | 0.478 | 0.486 | 0.513 | 0.52 | 0.525 |
| 0.5 | 10000 | 0.4922 | 0.4939 | 0.4959 | 0.5044 | 0.5061 | 0.5078 |
| 0.5 | 50000 | 0.4962 | 0.4968 | 0.4978 | 0.5018 | 0.5028 | 0.5036 |
| 0.5 | 100000 | 0.4974 | 0.4979 | 0.4986 | 0.5014 | 0.5021 | 0.5027 |
| 0.5 | 250000 | 0.4984 | 0.4987 | 0.4992 | 0.5008 | 0.5013 | 0.5017 |
| 0.5 | 500000 | 0.4988 | 0.4991 | 0.4994 | 0.5006 | 0.5009 | 0.5011 |
Посмотрим случаи с 10% конверсией и с низкой 0.01% конверсией, т.к. на них хорошо видны все особенности работы с сэмплированием.
При 10% конверсии картина выглядит довольно простой:

Точки — это края 5-95% доверительного интервала, т.е. делая сэмпл мы будем в 90% случаев получать CR на выборке внутри этого интервала. Вертикальная шкала — размер сэмпла (шкала логарифмическая), горизонтальная — значение коэффициента конверсии. Вертикальная черта — «истинный» CR.
Мы тут видим то же, что мы видели из теоретической модели: точность растет по мере роста размера сэмпла, при этом одна довольно быстро «сходится» и сэмпл получает результат близкий к «истинному». Всего на 1000 сэмпле мы имеем 8.6% — 11.7%, что для ряда задач будет достаточно. А на 10 тысячах уже 9.5% — 10.55%.
Куда хуже дела обстоят с редкими событиями и это согласуется с теорией:

У низкого коэффициента конверсии в 0.01% принципе проблемы на статистике в 1 млн наблюдений, а с сэмплами ситуация оказывается еще хуже. Ошибка становится просто гигантской. На сэмплах до 10 000 метрика в принципе не валидна. Например, на сэмпле в 10 наблюдений мой генератор просто 1000 раз получил 0 конверсию, поэтому там только 1 точка. На 100 тысячах мы имеем разброс от 0.005% до 0.0016%, т.е мы можем ошибаться почти в половину коэффициента при таком сэмплировании.
Также стоит отметить, что когда вы наблюдаете конверсию такого маленького масштаба на 1 млн испытаний, то у вас просто большая натуральная ошибка. Из этого следует, что выводы по динамике таких редких событий надо делать на действительно больших выборках иначе вы просто гоняетесь за призраками, за случайными флуктуациями в данных.
Выводы:
Несколько аспектов в грамотной организации семплинг кампаний
При проведении сэмплинга важно выбрать необходимый временной период для промо-мероприятий.Необходимо взвесить все за и против о том, в какое время суток необходимо проводить мероприятие.Например: кисломолочная продукция, скорее всего будет продаваться с утра, а пиво и сухарики – вечером. В этом случае логично провести семплинг, к примеру, сметана с йогуртом в единой акционной упаковке, продаётся весь день, а пачки из под сухариков меняются на целые – вечером
Нужно правильно рассчитывать объём пробника. Если вы продвигаете товар, например, майонез упаковка которого весит 200 грамм, а выдаёте 3 семпла по 70 граммов каждому покупателю магазина, то фактически вы бесплатно накормите своих потенциальных клиентов. Пробники то вы раздадите, но когда покупатели захотят совершить следующую покупку? Очевидно, что этому продукту не нужен такой объём саше.
Грамотно обозначить место проведения маркетинговой акции. Организовывать семплинг дорогого кетчупа в маленьком магазине нет смысла: затраты съедят все доходы от реализации продукции. Или если сделать промо-раздачу недорогого оливкового масла в гламурном алкомаркете – явно провальная затея, а вот дорогого сыра — нет. Его скорее всего будут брать к вину.
Проще всего делать семплинг там, где будет продаваться данный товар, потому что, обычно покупатель принимает решение спонтанно, на месте покупки, и искать понравившийся продукт он будет именно там, даже если промо-акция по раздаче саше была несколько недель назад.
Опытные промоутеры — залог успешной промо-акции. Внешний вид, общительность, возраст – это ключевые факторы при выборе промоутеров. Молодёжь не подходит для раздачи товаров для пенсионеров. Например, покупатель не станет доверять молодому человеку продающему пасту для чистки зубных протезов.
Определить цели семплинг кампании. Чаще всего, ознакомить потенциальных покупателей с вашим продуктом. Бюджет семплинг кампаний, как правило, не маленький – это и расходы на промоутеров, супервайзеров и их одежду; затраты на логистику и производство промо-продукции. Если вы предъявляете завышенные ожидания от семплинг-акции, например поднять продажи в 10 и более раз, то, возможно, вам стоит подумать о каком-то другом методе продвижения продукта.
Сэмплинг акции
Прежде чем проводить сэмплинг-акцию стоит взвесить все преимущества и недостатки метода. Главное, определить какая конкретно задача стоит в конкретном случае: повысить объем продаж, продвижение нового неизвестного пока продукта, повысить известность товарной марки или что-то еще.
Проведение сэмплинга задача дорогостоящая, поэтому стоит просчитать все заранее. Здесь надо учесть стоимость наладки производства для изготовления пробников, оплата персонала, стоимость аккредитации.
Кроме того, могут потребоваться расходы на специальную одежду для промоутеров.
Акцию можно проводить своими силами — это значит самим набирать персонал, договариваться о разрешении проведения акции в предполагаемом месте.
Или можно переложить эту ответственность на специализированные фирмы и только оплатить расходы. Если планируется крупномасштабная акция с участием нескольких городов или точек, то предпочтительнее привлечь профессионалов.
Виды сэмплинга
Сэмплинг — отличный способ стимулирования продаж в ритейле. Его организация в точках продаж позволяет подключать эмоции потенциальных покупателей и мотивирует их делать спонтанные покупки. Однако, сэмплинг не обязательно проводят на территории магазина или торгового центра. Некоторые компании предлагают образцы своей продукции прямо на улице. Ознакомьтесь подробнее с видами сэмплинга.
- Обмен (Switch-sampling). Подразумевает обмен наполовину пустой упаковки используемого товара на новый. Такой подход помогает клиенту сравнить качество аналогичных товаров.
- Сухой сэмплинг (dry sampling). Предполагает рекламу продукта в точке продажи. Потенциальным покупателям предлагают взять с собой пробник бальзама для волос, крема, зубной пасты или другого товара.
- Влажный сэмплинг (wet sampling). Предоставляет целевой аудитории возможность продегустировать товар на месте. Например, колбасные изделия, сыр, масло, йогурт и так далее.
- HoReCa сэмплинг (Hotel-Restaurant-Cafe sampling). Это дегустация алкогольных и безалкогольных напитков, а также сигарет. Такой сэмплинг чаще всего организовывают в ресторанах, кафе, гостиницах и преподносят как комплимент от заведения или подарок при заказе на определенную сумму.
- Домашний сэмплинг (house-to-house sampling). Предполагает рассылку примеров товара почтой. Это может быть мини-версия продукта или печатная реклама с образцами и многое другое.
Теперь, когда вы знаете виды сэмплинга, самое время узнать, как правильно его организовать.
Как организовать сэмплинг
- Установите цели и задачи сэмплинга
- Подберите продукт и установите объем сэмпла
- Выберите время проведения сэмплинга
- Выберите место проведения сэмплинга
- Соберите команду промоутеров
Чтобы организовать эффективный сэмплинг, воспользуйтесь следующими полезными рекомендациями.
Установите цели и задачи сэмплинга. Прежде чем приступать к организационным вопросам, подумайте, зачем вам нужна эта акция, чего вы хотите достичь с ее помощью. Подготовьте маркетинговый план и по пунктам пропишите пути достижения каждой задачи.
Подберите продукт и установите объем сэмпла
В этом вопросе важно полагаться на интересы и предпочтения целевой аудитории. Тщательно продумайте, что вы будете предлагать, как и в каком количестве
Пропишите расходы, необходимые для организации сэмплинга.
Выберите время проведения сэмплинга. Установите, когда лучше всего взаимодействовать с целевой аудиторией. Сэмплинг может проводится на протяжении всего дня или в какие-то определенные часы. Такой подход позволит сконцентрировать усилия на потенциальных покупателях и не распылять свои ресурсы.
Выберите место проведения сэмплинга. На основании данных о своей целевой аудитории выявите наиболее релевантные точки проведения акции. Подумайте, где больше всего ваших потенциальных покупателей. При этом помните, что клиент должен иметь возможность купить товар, иначе он может передумать и все усилия будут сведены к минимуму.
Соберите команду промоутеров. В этом вопросе важно учесть пол, возраст и другие характеристики, которые могут влиять на уровень доверия вашей целевой аудитории.
При правильном подходе сэмплинг способен увеличить объем продаж на 200-300%. Однако, эффективность не всегда можно измерить в денежном эквиваленте, ведь ознакомление целевой аудитории с продукцией это еще и работа на перспективу. Используйте инструменты ATL и BTL-рекламы, задействуйте мессенджеры и социальные сети, чтобы увеличить количество точек контакта с клиентом.
Пример (задача о моллюсках)
Сравним практически некоторые из описанных стратегий на наборе данных про моллюсков (набор данных взят с UCI machine learning repository). В нем представлены физиологические сведения об этих животных. Имеются следующие поля:
- пол;
- длина;
- диаметр (линия, перпендикулярная длине);
- высота;
- масса всего моллюска;
- масса без раковины;
- масса всех внутренних органов (после обескровливания);
- масса раковины (после высушивания);
- зависимая переменная: количество колец (в год на раковине моллюска появляется 1,5 кольца).
Изначально набор данных предназначен для решения задачи регрессии. По количеству колец на раковине определяется возраст моллюска. Для классификации в условиях несбалансированности создадим новую выходную переменную, принимающую только два значения. Для этого, предположим, что если количество колец у моллюска не превосходит 18, то для нас он будет считаться молодым, в противном случае – старым.
Также проимитируем ситуацию различия издержек и рассмотрим случаи, когда неверное отнесение старого моллюска к молодым может принести бо́льшие издержки, чем в случае неверной классификации фактически молодого.
Таким образом, мы получили набор данных с сильно несбалансированными классами, где значение «молодой» было присвоено 4083 записям (97,7%), а значение «старый» – 94 записям (2,3%). Далее стратифицированным сэмплингом были получены тестовый и обучающий наборы данных.
Прежде чем восстанавливать баланс между классами, вернемся к понятию издержек классификации. Во многих приложениях, таких как кредитный скоринг, директ-маркетинг, издержки при ложноположительной ($С_{10}$) классификации в несколько раз выше, чем при ложноотрицательной (обозначим их как $С_{01}$). При пороге отсечения 0,5 количество миноритарных примеров необходимо увеличить в $С_{10}/С_{01}$ раз (при условии что $С_{00} = С_{11} = 0$). Либо во столько же уменьшить мажоритарный класс (теоретическое обоснование этого утверждения изложено в работе ).
Сравним следующие подходы к восстановлению баланса между классами: случайное удаление примеров мажоритарного класса, дублирование примеров миноритарного класса, специальные методы увеличения числа примеров (алгоритмы SMOTE и ASMO).
Для алгоритмов SMOTE и ASMO количество ближайших соседей для генерации примеров установим равным 5.
Алгоритм ASMO признал набор данных нерассеянным (среди 100 ближайших соседей не нашлось даже 20 примеров из мажоритарного класса). Однако проигнорируем это сообщение и посмотрим, какой будет результат, если генерировать примеры, используя записи из каждого класса. Для кластеризации применен алгоритм k-means (k = 5).
После восстановления баланса строилась логистическая регрессия с порогом отсечения 0,5, и подсчитывались издержки. Результаты представлены на рисунке 7.
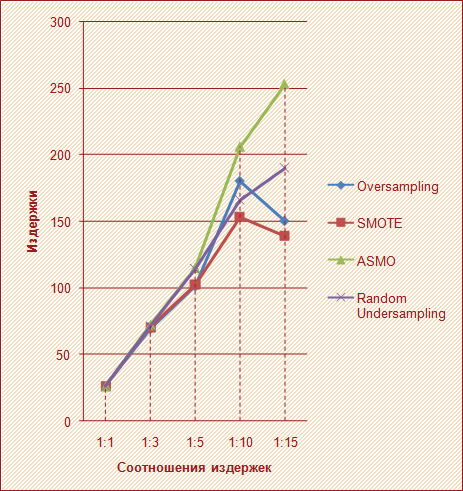
Из рисунка 6 видно, что наилучшим образом показал себя алгоритм SMOTE, так как издержки в данном случае оказались самыми меньшими. ASMO проявил себя хуже, однако стоит напомнить, что набор данных не рассеян и согласно данной стратегии необходимо было использовать SMOTE.
Итак, мы рассмотрели различные подходы сэмплинга для решения проблемы несбалансированности классов. Помимо него существуют стратегии, согласно которым происходит модификация алгоритма обучения, но их рассмотрение выходит за рамки данной статьи.
В таблице 1 приведено описание файлов с наборами данных, которые использовались в примере. Их можно найти в архиве.
Таблица 1 – Наборы данных
| Описание набора данных | Файл |
|---|---|
| Исходный набор данных: Abalone Data Set (классы не выделены) | abalone_data.txt |
| Исходный обучающий набор данных | dataset75.txt |
| Тестовый набор данных | testdataset.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:3 | syntsmote1_3.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:5 | syntsmote1_5.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:10 | syntsmote1_10.txt |
| Набор данных с искусственными примерами. Алгоритм SMOTE. Соотношение издержек 1:15 | syntsmote1_15.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:3 | syntasmot1_3.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:5 | syntasmot1_5.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:10 | syntasmot1_10.txt |
| Набор данных с искусственными примерами. Алгоритм ASMO. Соотношение издержек 1:15 | syntasmot1_15.txt |
Реализация розеток по Бернулли
Воспользуемся базовым классом розеток, поверх которого добавим особую функциональность изучаемого алгоритма. Затем прогоним этот новый класс через набор экспериментов с помощью тестовой программы для всех бандитских алгоритмов. Подробное описание базового класса розеток и тестовой системы дано в одной из предыдущих статей, а весь код лежит на Github.
Покажу реализацию сэмплирования Бернулли-Томпсона на примере класса :
В этом классе мы инициализируем и со значениями 1, чтобы получить равномерное распределение. Затем при обновлении мы просто увеличиваем если розетка возвращает вознаграждение, а в противном случае увеличиваем .
Функция sample выводит значение из бета-распределения, используя в качестве параметров текущие значения и .
Применение oversampling на практике.
Для примера возьмём популярный лимитер FabFilter Pro-L.
Внизу плагина можно увидеть следующие настройки:

Для чего нужны эти настройки?
Алгоритм лимитера часто должен очень быстро вносить изменения в звук, чтобы убрать пики при сохранении прозрачности и видимой громкости. Эти внезапные изменения могут привести к появлению aliasing (наложение спектров), что вызывает искажения и, как правило, снижает качество аудиосигнала. Передискретизация — это способ уменьшить это наложение, запустив процесс внутреннего ограничения с более высокой частотой дискретизации, которая кратна частоте дискретизации хоста.
Когда нужно включить oversampling ?
Когда процесс ограничения звука работает быстрее (с использованием короткого времени lookahead), и когда ограничение более интенсивно, то это приводит к более высокому уровню наложения спектров. Aliasing имеет эффект добавления ложных не музыкальных частот к звуковому сигналу, что ухудшает качество звука. Кроме того, aliasing вызывает более высокие пики между сэмплами, и они могут вызвать искажение позже, например, во время цифро-аналогового преобразования или преобразования в MP3. Но нельзя забывать и о недостатках oversampling, прежде всего увеличение нагрузки на процессор и некоторые проблемы из-за фазово-линейной фильтрации. Как правило, этот эффект настолько мал, что его невозможно услышать, но хорошо знать об этом и не слепо предполагать, что передискретизация это всегда хорошо.
Какой параметр oversampling выбрать?
В принципе достаточно 4-кратной (4x) или 8-кратной (8x) передискретизации. Такой параметр уже значительно уменьшит алиасинг и не вызовет чрезмерной загрузки процессора. Опции 16x и 32x могут привести к еще более высокому качеству звука, но для большинства систем это слишком сложно для работы в режиме реального времени, особенно если в сеансе есть и другие плагины. Вы можете использовать эти опции при рендеринге в автономном режиме.
Лимитирование и oversampling
Если True Peak Limiting включено, FabFilter Pro-L 2 гарантирует, что истинные пики на выходе не будут превышать потолочный уровень, установленный параметром Output Level в нижней панели. Однако, если передискретизация отключена, будет генерироваться больше пиков между сэмплами, поэтому лимитеру придется проделать большую работу, чтобы удержать их ниже верхнего уровня выходного сигнала. Включение передискретизации (например, с опцией 4x) уменьшит пики между выборками, что позволяет лимитеру увеличить общий выходной уровень и кажущуюся громкость. Короче говоря, рекомендуем использовать передискретизацию в сочетании с true peak, чтобы получить наилучшие результаты.
Спасибо, что читаете New Style Sound (). на новости или RSS и делитесь статьями с друзьями. Что такое RSS (читать). Скачивайте также бесплатные плагины на сайте.
Сэмплирование Бернулли-Томпсона
Давайте в качестве введения, и чтобы легче было работать, упростим задачу с поиском розетки. Вместо того, чтобы каждая розетка возвращала разное количество заряда, пусть они либо заряжают, либо нет. Тогда у вознаграждения будет два возможных значения: 1 — розетка заряжает, 0 — розетка не заряжает. Если у случайной величины лишь два возможных значения, её поведение можно описать с помощью распределения Бернулли.
Теперь вместо количества энергии в розетках меняется вероятность заряжания как такового. Нам нужно найти розетку с максимальной вероятностью заряжания, а не розетку с максимальным количеством энергии.
Итак, при сэмплировании Томпсона получается модель вероятностей вознаграждения. Когда доступность вознаграждения является бинарной (как в этом случае, да или нет), идеальной моделью для такой вероятности является бета-распределение. Подробнее о взаимосвязи бета-распределения и распределения Бернулли читайте здесь.
Бета-распределение зависит от двух параметров: и . Проще говоря, это счётчики числа успехов и неудач. Также у бета-распределения есть усреднённое значение, вычисляемое как:

Изначально мы не знаем, какова вероятность наличия энергии в какой-либо розетке, потому можно присвоить альфе и бете значение 1, что даст нам равномерное распределение (на иллюстрации 1 показано красным). Это начальное предположение называется априорной вероятностью: вероятность возникновения какого-то события до того, как мы получили какие-либо сведения о нем; в данном случае она представлена бета-распределением
Проверив розетку и получив вознаграждение, мы можем скорректировать наши ожидания того, что розетка работает. Такая новая вероятность после получения каких-то сведений называется апостериорной вероятностью. Она тоже представлена бета-распределением, но теперь мы обновили значения и на основе полученного вознаграждения.
Если розетка работает, то вознаграждение равно 1, и — счётчик успехов — увеличивается на 1. — счётчик неудач — не растёт. Если же мы не получим вознаграждение, то не изменится, а увеличится на 1. Чем больше мы собираем данных, тем сильнее бета-распределение начинает отличаться от прямой линии и становится всё более точной моделью вероятности усреднённого вознаграждения. Поддерживая значения и , алгоритм сэмплирования Томпсона может описать ожидаемое среднее вознаграждение и уровень его достоверности.
В отличие от жадного алгоритма, в котором на каждом временном шаге выбирается действие с наивысшим ожидаемым вознаграждением, даже если достоверность ожидания невысока, сэмплирование Томпсона берёт образцы из бета-распределения каждого действия, и выбирает действие с наивысшим возвращённым значением. Поскольку редко пробуемые действия имеют широкие распределения, (см. синюю кривую на иллюстрации 1), то у них больше диапазон возможных значений. Поэтому розетка, у которой сейчас низкое ожидаемое среднее вознаграждение, но которая тестировалась реже розетки с более высоким средним ожиданием, может вернуть большее выборочное значение и будет выбрана на следующем временном шаге.
На вышеприведённом графике синяя кривая имеет более низкое ожидаемое среднее вознаграждение, чем у зелёной кривой. Поэтому при жадном алгоритме будет выбрана зелёная розетка, а синяя никогда не будет выбрана. А сэмплирование Томпсона эффективно учитывает полную ширину кривой, которая у синей розетки может быть шире, чем у зелёной. В этом случае выбор может быть сделан в пользу синей розетки.
Чем чаще используется розетка, тем выше достоверность её ожидаемого среднего. Это отражено в сужении распределения вероятности, и выборочное значение будет браться из диапазона значений, которые ближе к реальному среднему (см. зелёную кривую на иллюстрации 1). В результате исследование (explore) уменьшается, а использование (exploit) растёт, потому что алгоритм начинает чаще выбирать розетки с более высокой вероятностью получения вознаграждения.
С другой стороны, розетки с низким ожидаемым среднем будут выбираться реже и в конце концов будут быстро выброшены из процесса выбора. Поэтому их истинное среднее может и не быть найдено. А поскольку нас интересует лишь розетка с наивысшей вероятностью получения вознаграждения, причём найти её нужно как можно скорее, то нас не волнует, что мы так и не получим всю информацию о плохо работающих розетках.